
Искусственный интеллект стремительно развивается и становится все более доступным для обычных пользователей. С появлением больших языковых моделей (LLM), таких как GPT и LLaMA, растет желание запускать эти модели локально на персональных компьютерах и ноутбуках. В этой статье мы приведем простое руководство по настройке Ollama – инструмента для локального запуска LLM на машинах с GPU и без него. Кроме того, в ней будет рассказано о развертывании OpenWebUI с помощью Podman для создания локального графического интерфейса для взаимодействия с Gen AI.
Что такое Ollama?
Ollama – это платформа, которая позволяет пользователям запускать LLM локально, не полагаясь на облачные сервисы. Она разработана для удобства пользователей и поддерживает различные модели. Запуская модели локально, пользователи могут обеспечить большую конфиденциальность, сократить время ожидания и сохранить контроль над своими данными.
Настройка Ollama на машине
Ollama можно запускать на машинах с выделенным GPU или без него. Ниже описаны общие шаги для обеих конфигураций.
1. Предварительные условия
Прежде чем приступить к работе, убедитесь, что у вас есть следующее:
- Система под управлением Fedora или совместимого дистрибутива Linux.
- Установлен Podman (для развертывания OpenWebUI)
- Достаточное дисковое пространство для хранения моделей
Для машин с графическими процессорами вам также понадобятся:
- Nvidia GPU с поддержкой CUDA (для более высокой производительности)
- Правильно установленные и настроенные драйверы NVIDIA
2. Установка Ollama
Ollama может быть установлена с помощью команды, состоящей из одной строки:
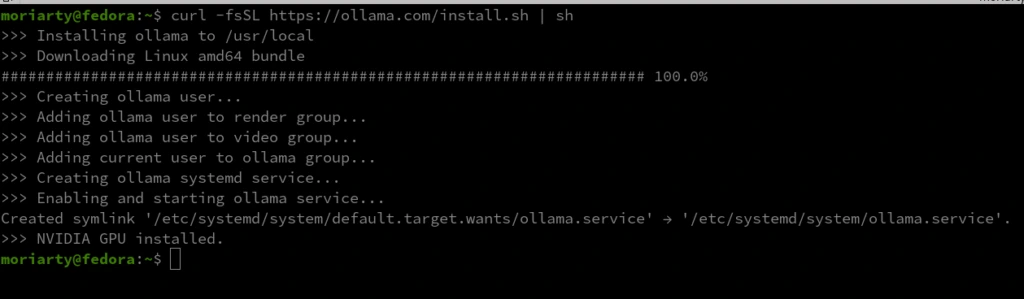
curl -fsSL https://ollama.com/install.sh | sh
После установки убедитесь, что Ollama правильно настроена, запустив программу:
ollama --version
Запуск LLM локально
После настройки Ollama вы можете загрузить понравившуюся модель и запустить ее локально. Модели могут быть разного размера, поэтому выбирайте ту, которая соответствует возможностям вашего оборудования. Например: Я бы лично использовал модель llama3.3 70B. Это около 42 Гб и может подойти не всем. Для каждого есть своя модель, даже для Raspberry Pi. Пожалуйста, найдите ту, которая подойдет для вашей системы. Подобрать можно здесь.
На машинах без GPU Ollama будет использовать вычисления на базе CPU. Хотя это медленнее, чем обработка на GPU, это все еще будет работать для основных задач.
Как только вы закончите, запустите ollama run и все заработает!

Развертывание OpenWebUI с помощью Podman
Для пользователей, предпочитающих графический интерфейс пользователя (GUI) для взаимодействия с LLM, OpenWebUI является отличным вариантом. Следующая команда развертывает OpenWebUI с помощью Podman, обеспечивая беспроблемную локальную установку.
1. Загрузка контейнера OpenWebUI
Начните с извлечения образа контейнера OpenWebUI:
podman run -d --network=host -v open-webui:/app/backend/data -e OLLAMA_BASE_URL=http://127.0.0.1:11434 --name open-webui --restart always ghcr.io/open-webui/open-webui:main

2. Запуск контейнера OpenWebUI
После того как образ загружен, запустите его; убедитесь в этом, запустив podman ps для получения списка существующих контейнеров. Зайдите в интерфейс OpenWebUI, открыв веб-браузер и перейдя по адресу localhost:8080.

Open WebUI поможет вам создать одну или несколько учетных записей администратора и пользователя для запроса LLM. Функциональность больше похожа на RBAC – вы можете настроить, какую модель может запрашивать пользователь и какой тип генерируемых ответов он должен выдавать. Эти функции помогают установить лимиты и права для пользователей, которые собираются предоставлять учетные записи для определенных целей.
В левом верхнем углу мы должны иметь возможность выбирать модели. Вы можете добавить больше моделей, просто запустив ollama run и обновив localhost после завершения выборки. Это должно позволить вам добавить несколько моделей.
Взаимодействие с графическим интерфейсом
Запустив OpenWebUI, вы можете легко взаимодействовать с LLM через графический интерфейс на основе браузера. Это упрощает ввод подсказок, получение результатов и тонкую настройку параметров модели.
Использование LLaVA для анализа изображений
LLaVA – это расширение языковых моделей, интегрирующее возможности зрения. Это позволяет пользователям загружать изображения и запрашивать модель о них. Ниже описаны шаги для локального запуска LLaVA и выполнения анализа изображений.
1. Извлечение контейнера LLaVA
Начните с извлечения модели LLaVA: ollama pull llava
2. Запуск LLaVA и загрузка изображения
После загрузки модели зайдите в интерфейс LLaVA через веб-интерфейс в браузере. Загрузите изображение и введите запрос, например:

LLaVA анализирует изображение и генерирует ответ на основе его визуального содержания.
Другие примеры использования
Помимо анализа изображений, такие модели, как LLaVA, могут использоваться для:
- Оптического распознавания символов (OCR): Извлечения текста из изображений и отсканированных документов.
- Мультимодальное взаимодействие: Объединение текстовых и графических данных для более богатого взаимодействия с ИИ.
- Визуальный контроль: Ответы на конкретные вопросы по изображениям, например, определение ориентиров или объектов.
Заключение
Следуя этому руководству, вы сможете создать локальную среду для запуска генеративных моделей ИИ с помощью Ollama и OpenWebUI. Независимо от того, есть ли у вас высокопроизводительный GPU или просто система на базе CPU, такая настройка позволит вам исследовать возможности ИИ, не полагаясь на облако. Локальный запуск LLM обеспечивает большую конфиденциальность, контроль и гибкость – ключевые факторы как для разработчиков, так и для энтузиастов.
Удачных экспериментов!





Комментарии (0)