


Grep – это небольшая UNIX-программа для поиска совпадающих шаблонов. Впервые она появилась в V6 UNIX, а сейчас ее можно найти практически в любой UNIX-подобной системе, такой как Linux, macOS и даже BSD. В этой статье я расскажу об основах Grep и покажу вам несколько примеров использования программы для решения повседневных задач.
Основы использования Grep
По своей сути Grep – это простая и понятная программа. Она принимает входные данные, находит в них нужный текст и печатает совпадения в виде выходных данных. Grep может обрабатывать практически любой простой текст. Это позволяет ему читать ввод, поступающий от других команд, и просматривать файлы напрямую.
Самый простой способ начать работу с Grep – это прочитать данные из текстового файла. Например, следующая команда выводит содержимое моего файла sample.txt:
grep '' sample.txt
Далее вы можете использовать эту функцию для поиска и нахождения определенных фрагментов текста в ваших текстовых файлах:
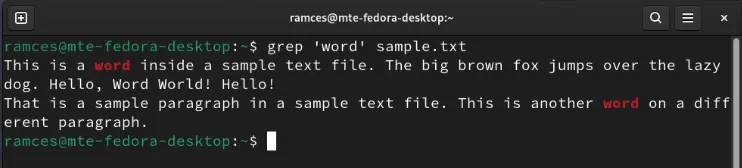
grep 'word' sample.txt
Вы также можете использовать Grep с UNIX pipes, что позволяет объединить несколько программ в одну команду:
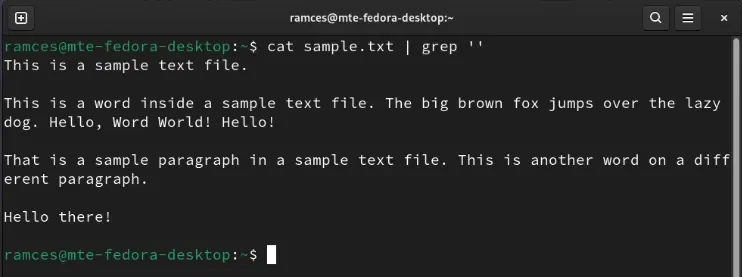
cat sample.txt | grep ''
Поиск файлов в каталоге
Одна из самых простых задач, которые можно решить с помощью Grep, – это поиск файлов в списке каталогов. Для этого вы можете отправить вывод команды ls через UNIX-трубу прямо в Grep.
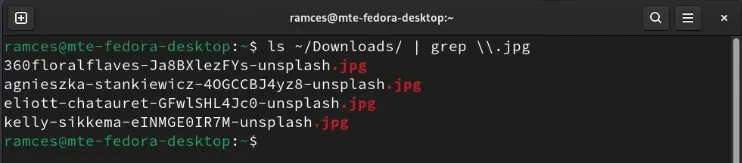
Следующая команда выведет на печать и выделит все файлы в папке Downloads с расширением .jpg:
ls ~/Downloads | grep \\.jpg
Вы также можете отправить Grep более сложный вывод ls и использовать его для сопоставления с образцом. Например, ниже перечислены все файлы в каталоге с размером менее 1 МБ:
ls -lh ./ | grep .K

Забудьте про случай
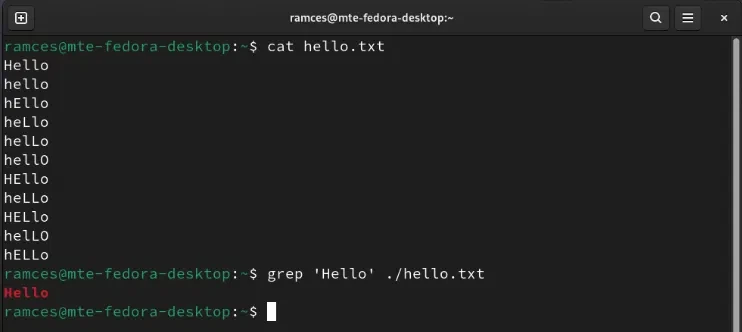
По умолчанию почти все программы в UNIX-подобных системах чувствительны к регистру. Это означает, что система воспринимает строку Hello иначе, чем hello, hEllo и helLo.
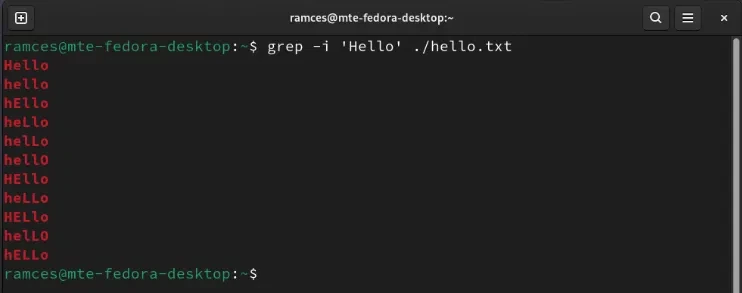
Такое поведение может быть неприятным при поиске строк внутри файлов. Например, в эссе может быть одновременно Hello и hello. Чтобы решить эту проблему, запустите Grep с флагом -i, за которым следует строка, которую вы хотите найти.
grep -i Hello hello.txt
Рекурсивный поиск
Grep может искать в нескольких файлах или каталогах одновременно. Это полезно, если вы работаете над проектом с несколькими файлами и хотите узнать, где в каталоге встречается та или иная строка текста. Например, следующая команда ищет слово MakeTechEasier в каталоге sample:
grep -r 'MakeTechEasier' ./sample

При этом использование флага -r также заставит Grep просмотреть каждый файл в целевом каталоге. Это может стать проблемой, если в папке, в которой выполняется поиск, есть и нетекстовые файлы. Чтобы избежать этого, запускайте Grep с флагом -I:
grep -rI 'MakeTechEasier' ./sample
Сопоставление файлов, содержащих строку
Кроме того, что Grep показывает, где определенная строка встречается в различных файлах, вы также можете использовать Grep для создания списка файлов, содержащих целевой текст. Это полезно, если вы хотите узнать, содержит ли файл определенную строку, но не хотите, чтобы Grep выводил в терминал каждый ее экземпляр.
Для этого запустите Grep с флагами -r и -l, после чего укажите строку, которую вы хотите найти, и каталог, который вы хотите просмотреть:
grep -rl MakeTechEasier ./sample

Вы даже можете заключить команду Grep внутри под-оболочки Bash, чтобы создать несколько условий для сопоставления текста. Например, следующая строка кода вернет только те файлы, которые содержат Hello и MakeTechEasier в папке sample:
grep -rl MakeTechEasier $(grep -rl Hello ./sample)

Найдите противоположность
Помимо прямого поиска, Grep может возвращать результаты, которые не соответствуют вашим исходным критериям. Хотя сначала это может показаться нелогичным, это может быть полезно в случаях, когда вам нужно выделить ошибки и аномалии из введенного текста.
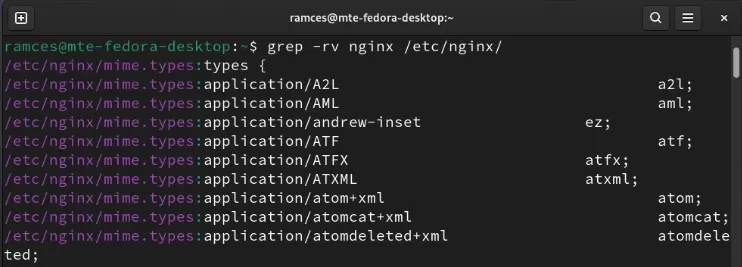
Для этого запустите Grep с -v вместе с другими флагами, которые вы хотите включить. Например, следующая команда будет рекурсивно искать каждый файл в моей папке /etc/nginx и возвращать все строки, которые не содержат строку nginx:
grep -rv 'nginx' /etc/nginx
Слова и строки
Также может быть полезно указать Grep искать полные слова или строки, а не все, что содержит определенный шаблон. Это полезно, если вы подбираете строку символов, которые встречаются во многих словах. Например, при поиске слова it будет получено множество ложных срабатываний, поскольку это обычная строка, которую можно встретить в словах.
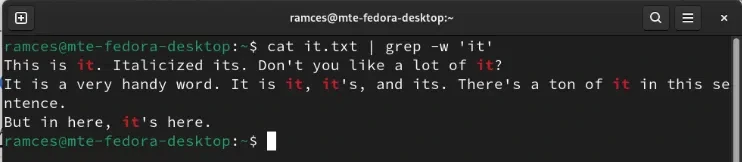
Чтобы исправить это, вы можете запустить Grep с флагом -w, за которым следует слово, которое вы хотите найти:
cat it.txt | grep -w it
Вместо того чтобы выводить каждое слово, содержащее шаблон, Grep выведет только его. С помощью флага -x он делает то же самое для целых строк, так что если вы ищете фразу или одну строку в файле конфигурации, это может очень помочь.

Добавление номеров строк в вывод Grep
Номера строк – важная часть отладки программ и вычитки текста. Они позволяют точно указать местоположение конкретной функции или предложения, что значительно ускоряет процесс исправления и корректировки.
В связи с этим Grep имеет возможность выводить номера строк в стандартный вывод. Для этого запустите программу с флагом -n, а затем введите строку, которую вы хотите проверить:
grep -n main ./my-code.c

С помощью UNIX pipes вы также можете изменить вывод Greps и выводить только номера строк, в которых находится искомый текст. Это позволяет намного чище и проще разбирать большие тексты:
grep -n Sed essay.txt | cut -f 1 -d :

Использование расширенного регекса в Grep
Grep использует набор метасимволов Basic Regular Expression (BRE) для сопоставления и фильтрации текстовых строк. Хотя это обычно подходит для большинства задач, некоторые пользователи могут счесть это ограничением, особенно при работе с группами шаблонов.
Для решения этой проблемы в большинстве реализаций Grep используется флаг -E, который позволяет программе анализировать метасимволы расширенного регулярного выражения (Extended Regular Expression, ERE). Например, следующая команда будет работать только с флагом -E:
printf "hello\nhellooooo\n" | grep -E .*o{2}$

Примечание: GNU-версия Grep использует некоторые функции ERE по умолчанию. Однако для сохранения совместимости с другими UNIX-подобными системами лучше использовать -E, когда вы используете ERE.
Кроме того, в Grep есть специальный режим, в котором полностью отсутствуют все функции Regex. Чтобы воспользоваться этим режимом, запустите программу с флагом -F, после которого следует обычная строка:
grep -F [MakeTechEasier] ./fixed.txt

Добавление смежных строк в вывод Grep
Одно из основных достоинств Grep – показывать, где появляется текст в файле или входном потоке. Однако бывают случаи, когда просто знание точного местоположения строки не помогает при устранении проблем. Например, журнал аварийных ситуаций обычно предоставляет дополнительный контекст, прежде чем вывести традиционное сообщение Segmentation Fault.
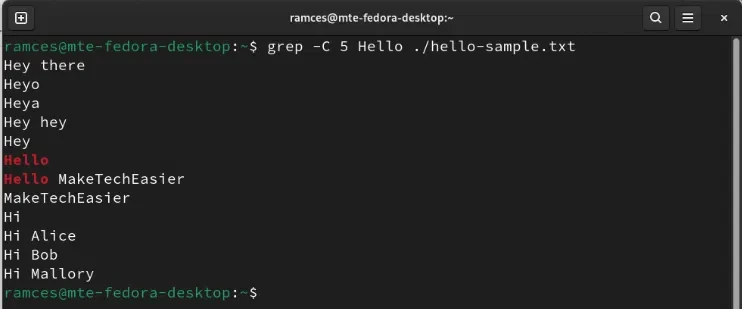
Один из способов решить эту проблему – запустить Grep с флагом -C, за которым следует количество строк, которые вы хотите напечатать вокруг целевого текста. Следующая команда печатает по пять строк до и после совпадения текста:
grep -C 5 'Hello' ./hello-sample.txt
С помощью флагов -B и -A вы также можете настроить, будет ли Grep печатать только контекст до или после совпадения. Например, следующая команда выведет десять предыдущих строк после целевой строки:
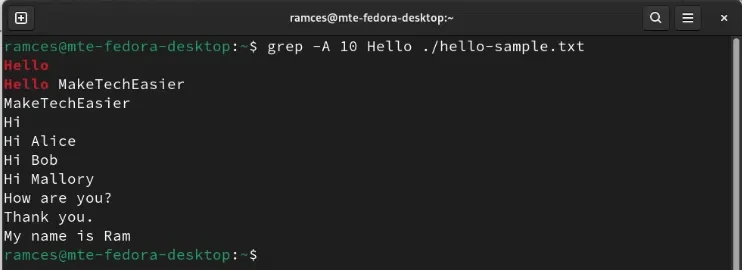
grep -A 10 'Hello' ./hello-sample.txt
Ознакомившись с основами работы Grep и его использованием в повседневных задачах, вы можете сделать первый шаг к пониманию командной строки и основных утилит UNIX. Откройте для себя этот очень разнообразный и глубокий мир, узнав, как работает sed в Linux.



Комментарии (0)