Исторически сложилось так, что разработчикам было сложно использовать профилировщики в Linux из-за особенностей сборки дистрибутивов. В Fedora Linux это недавно было исправлено, так что каждый может внести свой вклад в повышение скорости, эффективности и надёжности Linux. В этой статье мы расскажем вам о том, как использовать профилирование производительности в Fedroa Linux. В ней также будет рассказано о том, как работает профилирование.
Программный профайлер помогает разработчикам улучшить производительность, характеризуя то, что происходит на компьютере в течение определенного периода времени.
Эта информация помогает определить, какие изменения необходимы для снижения энергопотребления, ускорения выполнения длительных задач или даже для поиска труднодоступных ошибок.
В конечном итоге эти изменения становятся частью операционной системы и приложений, которые попадают к пользователям в предстоящем выпуске!
В Fedora Linux 38 появились «указатели кадров» для улучшения качества информации, записываемой профилировщиками. Затем в Fedora Linux 39 был значительно переработан Sysprof (инструмент профилирования всей системы), чтобы упростить анализ и принятие мер на основе этой более качественной информации.
Первое, что нам нужно сделать, это установить Sysprof. Он содержит как привилегированный демон, так и интерактивное GTK-приложение.
sudo dnf install sysprof
Давайте откроем GTK-приложение и используем его для записи того, что происходит в нашей системе. Приложение уже настроено по умолчанию, поэтому мы можем сразу нажать «Record to Memory».
Далее появится маленький индикатор записи. С его помощью можно остановить запись по завершении интересующей нас задачи.
Во время работы профилировщика мы занимаемся тем приложением, о котором хотим получить больше информации. В качестве альтернативы мы можем ничего не делать и просто посмотреть, что делает система во время простоя.
Примерно через двадцать секунд мы кликаем Stop Recording, и появляется интерактивный интерфейс. Теперь его можно использовать для изучения того, что произошло.
Обратите внимание, что вы также можете использовать команду sysprof-cli для записи профилей. Чтобы открыть и изучить их, используйте приложение Sysprof. Это может быть полезно при использовании SSH для доступа к удаленному хосту.
Остановка записи приводит к отображению каллграфа. (Мы также можем визуализировать запись с помощью пламеграфа)
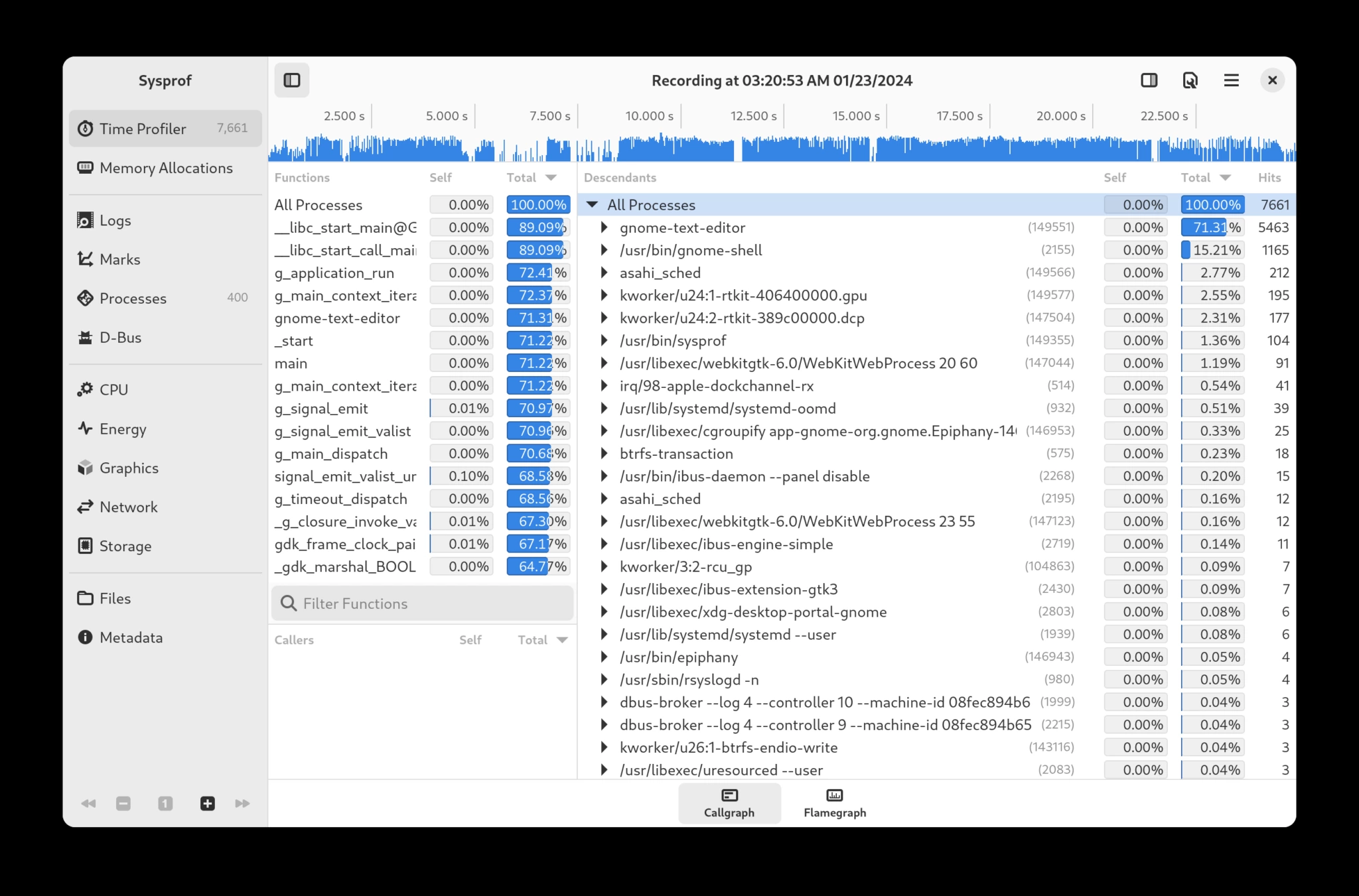
Выбор Flamegraph в нижней части каллграфа представит данные в виде пламеграфа, как показано ниже.
Используйте пламеграфы, чтобы получить высокоуровневый обзор происходящего. Зачастую их легче интерпретировать, чем коллграф.
Интерпретация результатов
Интерпретация – само по себе искусство, но суть в том, чтобы искать участки, которые выглядят большими для того, что они должны делать. Скептический взгляд может далеко завести.
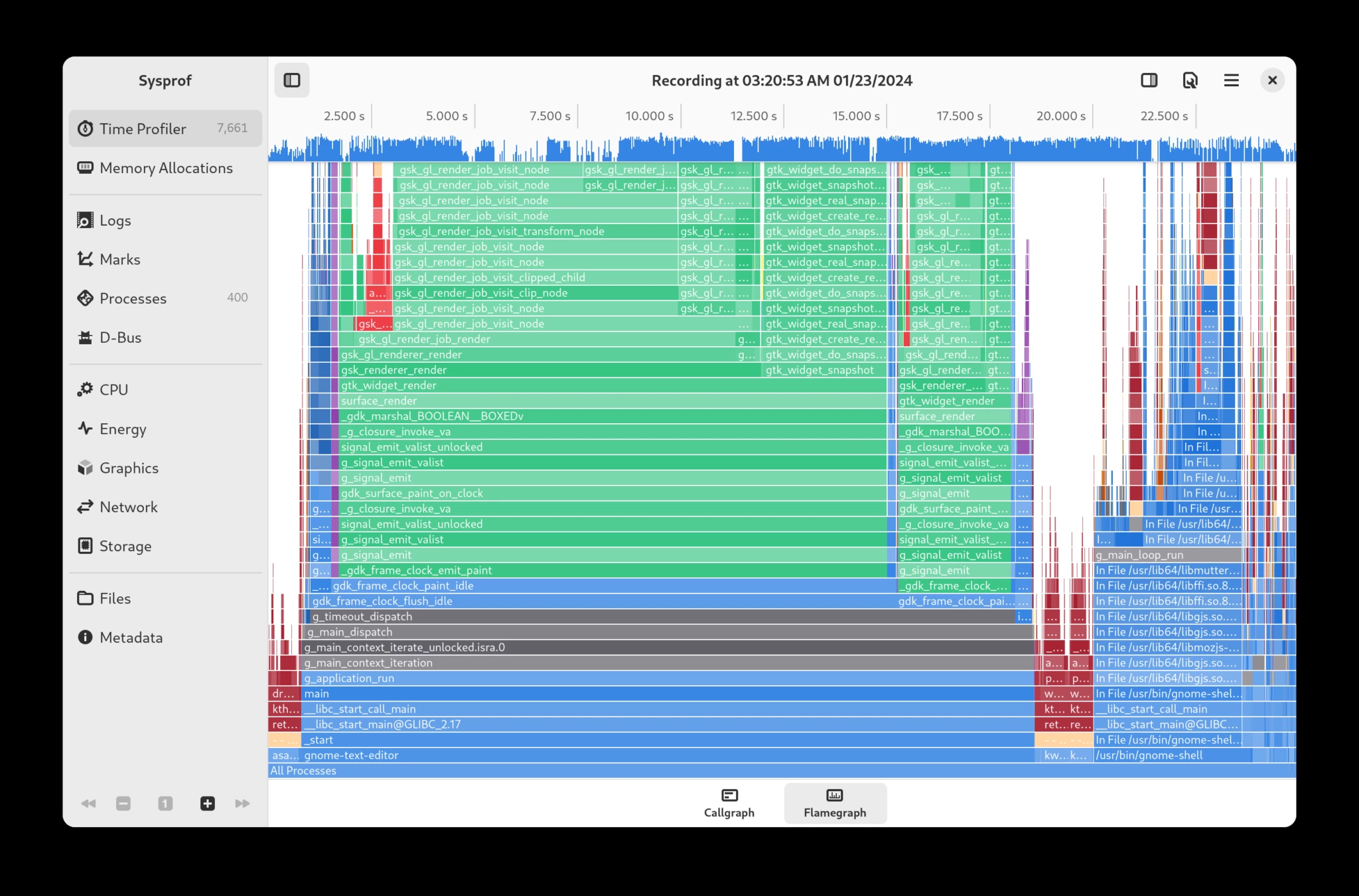
Например, здесь я проанализировал работу текстового редактора GNOME при прокрутке большого исходного файла на языке C, чтобы посмотреть, как он справляется.
То, что я записал здесь, показывает, что большая часть времени, которое требуется GTK для отрисовки окна, связана с номерами строк. Это почти в два раза больше, чем на отрисовку видимого содержимого файла! Мы можем убедиться в этом, сравнив размеры draw_text() и gtk_source_gutter_snapshot().
Если мы погрузимся в функцию gtk_source_gutter_renderer_text_snapshot_line() в flamegraph, то увидим, что она выполняет много работы с Pango и Harfbuzz, которую, возможно, мы могли бы избежать.
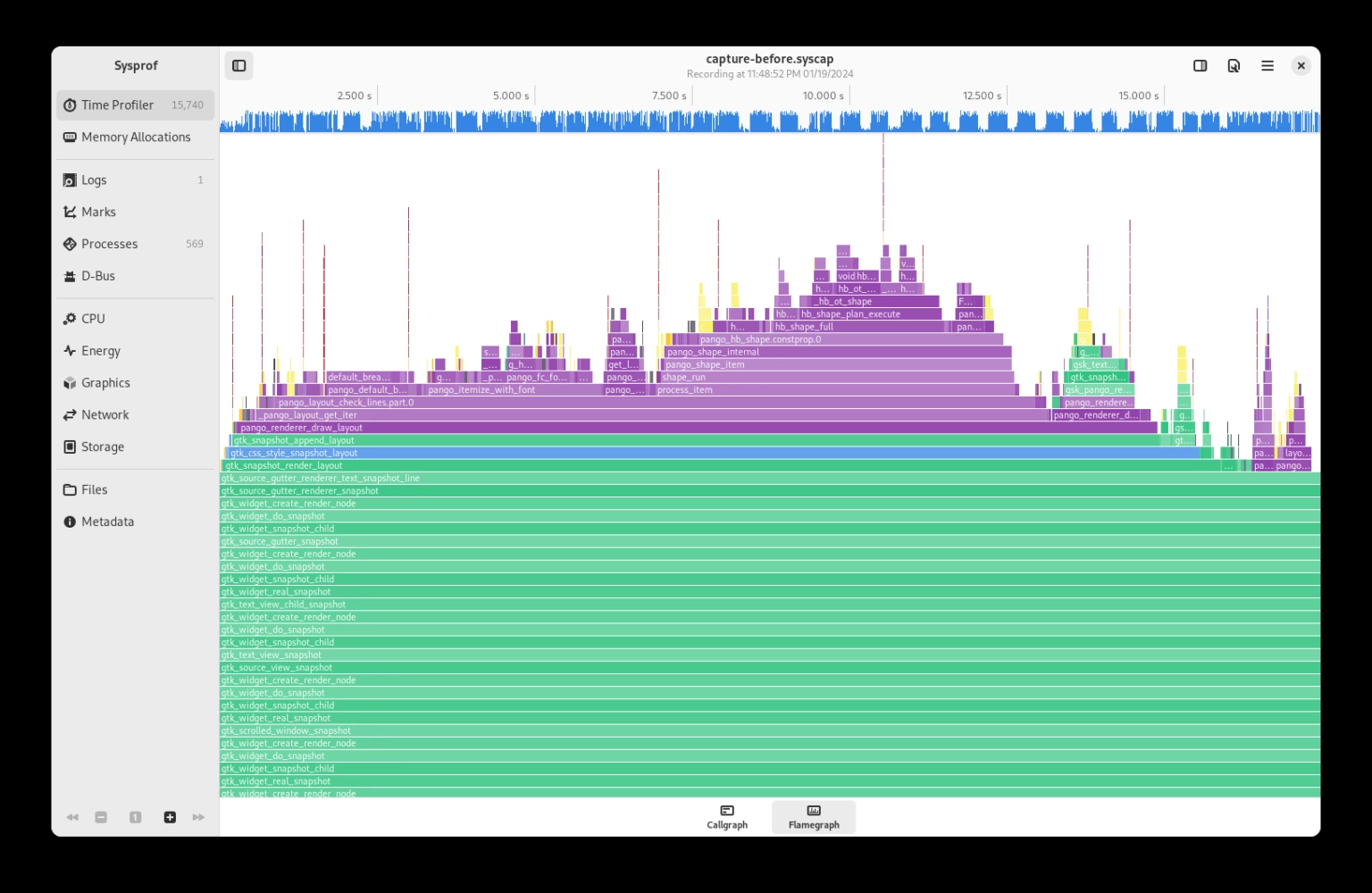
После изменений –
GtkSourceGutterRendererLines выполнения тестов видно, что накладные расходы на Pango и Harfbuzz почти полностью устранены.
Тестирование приложения подтверждает, что производительность прокрутки действительно стала более плавной!
Повышение производительности часто напоминает игру. Проведите измерения, записав, что делает ваша система, а затем выберите что-то, что окажет влияние. Ищите то, чего вы не ожидали увидеть. Худшее, что может случиться, – это то, что вы узнаете, как работает тот или иной компонент вашей операционной системы!
Получение лучших имен функций
Иногда Sysprof не может определить имя функции для определенного фрагмента кода. Вместо этого он может назвать функцию чем-то вроде In File libthing.so 0×1234.
Вы можете улучшить ситуацию, установив пакет debuginfo для этого приложения или библиотеки. Например, чтобы получить пакет debuginfo для GTK 4, можно выполнить следующую команду.
sudo dnf debuginfo-install gtk4
Микро- и макропрофилирование
Иногда вы хотите сделать небольшой фрагмент кода чрезвычайно быстрым, например сравнить строки с помощью strcmp(). Это «микропрофилирование».
Иногда вы хотите сосредоточиться на целой системе, состоящей из взаимосвязанных частей. Это «макропрофилирование» или, как я предпочитаю его называть, «профилирование всей системы».
Эта статья посвящена «профилированию всей системы», потому что это дает самый широкий эффект для изменений. Она позволяет увидеть на высоком уровне, что происходит в различных процессах и как поведение одной программы может вызвать проблемы с производительностью в других.
Для профилирования всей системы необходим «профилировщик выборок». Профилировщик выборки работает путем записи «трассировки стека» того, что делает процесс, много раз в секунду.
В отличие от «трассирующего профилировщика», который пытается записать каждый вход и выход функции. Профилировщик выборки, как правило, имеет фиксированную верхнюю границу накладных расходов, в то время как профилировщик трассировки имеет накладные расходы на каждый вызов/возврат функции. Простые профилировщики трассировки могут вводить в заблуждение при поиске проблем с производительностью.
Что содержится в трассировке стека?
Трассировка стека содержит один или несколько «указателей инструкций». Каждый указатель инструкции – это адрес памяти для инструкции процессора. По мере того как функция вызывает другую функцию, трассировка стека будет становиться глубже. После возвращения он становится более поверхностным. Иногда одна функция настолько сложна, что компилятор разбивает ее на более мелкие функции, но механика остается прежней.
Исполняемый код приложения «отображается» в память в различных диапазонах адресов. Если вы знаете, какой файл отображен по адресу, на который указывает указатель инструкции, вы можете узнать, какая функция была запущена. Это происходит потому, что исполняемый файл (ELF) может содержать диапазон адресов для символа.
Когда диапазон адресов отсутствует, он иногда указывает на другой файл, используя специальную секцию под названием «.gnu_debuglink». Этот файл, на который ссылаются, будет содержать информацию, которую мы ищем.
Запись трасс стека
Большинство профилировщиков выборки в Linux работают с помощью подсистемы «perf» ядра Linux. Она предоставляет крючки для записи трассировки стека через регулярные интервалы времени как из ядра, так и из пользовательского пространства.
Это делается путем «разворачивания» стека для определенной задачи. Некоторые задачи могут использовать syscall для перехода из пользовательского пространства в ядро. Perf в Linux может объединить это в один стек-трассировку, предоставляя ценную информацию о производительности приложения.
Во многих конфигурациях ядра Linux разворачивает задачи внутри ядра, используя ORC с опущенными указателями кадров. Размотчик ORC генерирует информацию о том, как разворачивать из любого указателя инструкций внутри ядра. Его формат краток и обеспечивает быструю размотку без использования указателей кадров.
ORC в настоящее время не подходит для пользовательского пространства, поэтому необходимо использовать другой инструмент.
В задачах пользовательского пространства используется размотчик «кадр-указатель». Он обходит каждый кадр стека, используя указатели кадров, скомпилированные в ядре. Если программа была скомпилирована без указателей кадров, то размотка обычно останавливается в точке входа задачи, предоставляя приложению-профайлеру неполные результаты.
Указатели кадров
Указатель кадра – это техника, которая создает «связанный список» из кадров стека. При вызове функции регистр текущего кадра стека сохраняется в стеке. Затем регистр обновляется и указывает на новую позицию стека. При возврате из функции выполняется обратная операция.
Это позволяет обходить каждый кадр стека, начиная с текущей позиции стека, поскольку вы знаете, куда смотреть дальше из сохраненного значения регистра. Отсюда – «связанный список».
Эта техника позволяет очень быстро построить трассировку стека, но за счет несколько большего размера двоичных файлов, поскольку для отслеживания кадров стека приходится вставлять прологи и эпилоги вызовов функций.
Однако увеличение числа инструкций может увеличить нагрузку на кэш инструкций процессора, что, теоретически, может привести к снижению производительности.
Компиляторы, опускающие указатели кадров
Некоторые виды оптимизаций компилятора усложняют определение функции до такой степени, что это невозможно сделать в режиме реального времени без замедления работы системы.
Это происходит потому, что компилятор может полностью оптимизировать использование «регистра указателя кадра». Идея этой техники заключается в том, что она освобождает один дополнительный регистр общего назначения для сложных операций в вашем приложении или библиотеке.
Отказ от использования кадровых указателей имел большой смысл во времена 32-битных x86, поскольку регистры общего назначения были так малочисленны. За счет усложнения компилятора, который должен отслеживать, какие именно регистры необходимы в ряде функций, чтобы при необходимости вставить указатель кадра.
Некоторые архитектуры требуют использования указателей кадра, например, aarch64. Отказ от них там нецелесообразен.
На современных машинах x86_64 отказ от указателей кадров редко дает прирост производительности, разве что в некоторых микробенчмарках.
Почему значения по умолчанию компилятора имеют значение
Указатели кадров были добавлены в Fedora Linux путем изменения флагов компилятора по умолчанию для RPM. Часто спрашивали, почему все должно быть скомпилировано с указателями кадров, а не только библиотека здесь или там или только на машинах разработчиков?
Ответ заключается в том, что любая функция в трассировке стека может нарушить возможность разворачивания. Если у вас есть 10 кадров стека, но в одном из них отсутствует указатель кадра, то размотка стека может найти только 5 кадров.
Это имеет значение, когда вы хотите визуализировать свой профиль. Если вы не можете добраться до корневого кадра стека вашего потока, то вы не сможете достоверно визуализировать происходящее в программе с помощью коллграфов или пламяграфов.
Отслеживание проблем с производительностью в производстве требует возможности получить представление об этих системах. Когда проблема с производительностью возникает на производстве, вы не можете сделать первый шаг к пониманию, требующий установки ряда различных библиотек, приложений или специализированного дистрибутива Linux. Это может привести к дальнейшему разрушению производственной среды!
Аналогично, компьютеры пользователей Fedora Linux – это наше производство. Если первым шагом к решению проблемы производительности вашей системы будет установка совершенно другого набора пакетов, то мы вряд ли получим сотрудничество пользователей в устранении ошибок производительности. А это никому не выгодно.
Альтернативы кадровым указателям
Кадровые указатели – не единственный способ размотать или сгенерировать трассировку стека. Альтернативы в настоящее время представляют некоторые проблемы в контексте профилирования.
DWARF и .eh_frame
Для построения трассировки стека в работающей программе часто используется специализированная виртуальная машина для отладки программ на языках C и C+. Отладочный формат DWARF содержит инструкции, которые могут быть оценены для разворачивания стека, учитывая любой указатель инструкции и текущие значения регистров. Аналогично, формат .ehframe предоставляет схожую информацию, используемую при обработке исключений в С. Поскольку приложения на языке C обязаны предоставлять такую информацию, данные .eh_frame могут использоваться и там.
Эти инструкции обычно довольно просты, но сама виртуальная машина допускает их усложнение. Ядро Linux удалило поддержку разворачивания с помощью DWARF и поэтому требует, чтобы разворачивание выполнялось автономно в пользовательском пространстве.
Чтобы выполнить это разворачивание в пользовательском пространстве, perf должен сначала захватить содержимое стека потока. Содержимое копируется в поток perf, который считывается профилировщиком.
Если все трассы стека не превышают жестко заданный при записи размер стека, вы рискуете получить усеченные трассы стека. И снова это может сделать точную визуализацию проблематичной. Это хорошо видно в приложениях, использующих графические наборы инструментов, которые регулярно имеют глубокие стеки.
Запись стеков потоков также происходит медленнее. Это может помешать тому, что вы пытаетесь профилировать. Это может увеличить нагрузку на память и хранилище.
eBPF Unwinding
В последнее время появился интерес к реализации разворачивания стека с помощью программ eBPF (Расширенный пакетный фильтр Беркли) в ядре Linux. Это перспективное направление для профилирования производительности в Linux!
Одним из ограничений методов разворачивания eBPF является то, что он должен быть загружен таблицами, используемыми для разворачивания.
Это создает дополнительное давление на память в системах, где вы не сможете протестировать условия, которые вы пытались профилировать.
Он также должен реагировать на запуск новых процессов. Это проблематично, если вам нужно профилировать запуск приложения. Особенно в таких сценариях, как рабочий стол, где множество процессов запускается и взаимодействует одновременно.
Контейнеры представляют собой дополнительную проблему, поскольку разрешение файлов, необходимых для построения таблиц, может осуществляться через непрозрачную файловую систему типа FUSE или удаляться с диска. Если у вас нет этой информации, то вам нечего будет разматывать.
Сравните это с использованием фреймовых указателей, где вы, по крайней мере, получите трассировку стека даже без доступа к информации о символах.
SHSTK и LBR
Shadow Stacks (SHSTK) и Last Branch Records (
LBR) могут обеспечить подходящую аппаратную поддержку для разворачивания стека в будущем без использования фрейм-указателей.
На момент написания статьи пока нет широкой поддержки для них в цепочке инструментов или на большом количестве систем, используемых сообществом Fedora.
Мы хотим, чтобы сообщество Fedora могло участвовать в повышении производительности, что означает поддержку уже имеющегося у них оборудования.
В будущем могут появиться возможности компиляции библиотек для определенных ревизий оборудования, которые гарантированно будут иметь поддержку SHSTK или LBR. В них потенциально могут отсутствовать указатели кадров.
SFrame
Еще одним перспективным усовершенствованием по сравнению с фрейм-указателями является SFrame. Он предоставляет технику, аналогичную ORC, но для пользовательского пространства. Пока еще рано говорить о том, что будет с SFrame в дистрибутивах Linux, но его поддержка есть в binutils.
В настоящее время мы знаем, что он не такой компактный, как инструкции разворачивания DWARF, но обеспечивает более быструю поддержку разворачивания. Она также ограничена x86_64 и aarch64.
Развертка ядра также необходима для SFrame и потребует доступа к секции .sframe приложений и библиотек без страничных ошибок. Некоторые будущие работы над ядром могут позволить это изменить, хотя автор считает, что это потребует серьезных изменений в потоке событий perf.
Символизация
Чтобы сделать трассировку стека полезной, нам нужно перейти от указателей инструкций к именам функций и, если возможно, к номерам строк исходного кода.
Если указатель инструкции попадает в экспортируемый символ, то, скорее всего, мы сможем получить имя функции из ELF, загруженного в память. Если нет, то нам может понадобиться найти соответствующий ELF «debuginfo», который содержит более подробные ссылки от расположения адресов до имен функций.
Многие ошибочно полагают, что установка пакетов debuginfo поможет вам получить лучшие трассировки стека при профилировании. Эти пакеты влияют только на возможность получения более точных имен функций или местоположения исходного кода. Они не влияют на способность ядра Linux разворачивать указатели кадров.
После получения имени функции из ELF или соответствующего ELF debuginfo может потребоваться дополнительная деманганация. И C, и Rust могут предоставлять символы в нескольких форматах, которые необходимо преобразовать в человекочитаемый формат.
Пространства имен контейнеров
В Linux все чаще используются контейнеры как для разработки, так и для развертывания приложений. Пространства имен контейнеров используются независимо от того, что это – Podman, Docker systemd-nspawn или Flatpak.
Это добавляет сложности при символизации, поскольку процесс, выполняющий символизацию, может не иметь полного представления о пространстве имен контейнера. На самом деле, к моменту символизации этого процесса может уже и не быть.
Для того чтобы это работало, необходимо правильно разрешить как пространства имен PID, так и пространства имен Mount
Например, мы хотим найти местоположение /usr/lib/libglib-2.0.so для профилированного процесса. Можно было бы ожидать, что он будет находиться в том же месте. Однако в Linux существует концепция монтируемых пространств имен, и она лежит в основе контейнерной технологии. То, что один процесс видит для libglib-2.0.so, может сильно отличаться от другого профилированного процесса.
Помните, как нам нужно переводить ссылки .gnu_debuglink, отмеченные в ELF-секциях? Они также должны быть разрешены с использованием пространства имен монтирования профилируемого процесса.
В случае Flatpak отладочная информация о библиотеках и приложениях предоставляется отдельной отладочной средой выполнения, поэтому для получения подробных имен символов может потребоваться дополнительная трансляция путей.
В других случаях для проверки наличия нужного файла можно использовать номер устройства и inode. Если у вас файловая система FUSE, это вряд ли сработает, и потребуются специализированные обходные пути.
В некоторых случаях проект debuginfod может предоставить информацию о символах, хотя и с ущербом для производительности.
Субтома файловой системы
Многие пользователи, иногда неосознанно, используют более продвинутую функцию файловой системы, называемую «субтомами». Они могут создавать проблемы при профилировании, поскольку некоторые контейнеры могут не иметь доступа к одному и тому же субтому. А когда они получают доступ, он может быть смонтирован в другом месте.
Sysprof попытается смоделировать пространство имен монтирования как профилируемого процесса, так и самого себя, чтобы сделать наилучшую попытку определить местоположение приложений, библиотек и соответствующих им файлов отладочной информации.
Быстрая символизация
Даже при относительно коротких профилях у нас могут быть сотни тысяч указателей инструкций, которые необходимо символизировать. Каждый процесс в пользовательском пространстве имеет свою собственную структуру памяти, но адресное пространство ядра будет выглядеть одинаково.
Если символизация выполняется не быстро, люди будут обращаться к другим инструментам, которые могут не обеспечивать такой уровень детализации, как профилировщики программного обеспечения.
Чтобы сделать символизацию быстрой, Sysprof содержит интервальное дерево для каждого процесса, основанное на красно-черном дереве. Оно также содержит дерево для ядра.
Если мы знаем диапазон адресов функции, то все последующие поиски в этом диапазоне адресов могут быть выполнены без просмотра ELF-файлов на диске.
На практике это ускоряет символизацию настолько, что она кажется почти мгновенной.
Дополнительные источники данных
Иметь достоверные трассировки стека за определенное время – уже само по себе невероятно полезно. Но что, если бы вы могли соотнести их с другой системной информацией?
Sysprof включает интеграцию с множеством других источников данных, чтобы вы могли погрузиться в определенные периоды времени и посмотреть, что происходило.
Системные счетчики
Многие системные счетчики доступны для корреляции.
Они включают в себя как использование процессора, так и его частоту. Это может быть полезно для быстрого обнаружения и изучения проблем с производительностью системы.
Сетевые счетчики позволяют точно определить, когда был сделан сетевой запрос. Аналогичным образом дисковые счетчики позволяют увидеть, какой код выполнялся во время большого дискового ввода-вывода.
GTK и GNOME Shell
Одна вещь, которую мы хотим видеть на наших рабочих столах, – это плавная работа приложений и композиторов. Чтобы помочь нам в этом, Sysprof предоставляет информацию о тайминге кадров.
Как GTK, так и GNOME Shell могут экспортировать тайминг кадров в Sysprof, если они настроены. Это позволит вам увидеть, что происходило до того момента, когда был пропущено время выполнения кадра.
Профилирование памяти
В дополнение к профилированию на основе выборки, Sysprof может внедрить код для отслеживания выделения памяти в вашем приложении. Это может быть полезно, когда вы хотите найти части приложения, занимающие много памяти, которые могут выиграть от альтернативных решений.
JavaScript
Если ваше приложение использует GJS, поддерживаемый SpiderMonkey, Sysprof имеет интеграцию, которая позволит вам увидеть трассы стека JavaScript.
В отличие от Linux perf, здесь используется таймер внутри приложения, который останавливает интерпретатор JavaScript и разворачивает стек.
Для разработчиков приложений, пытающихся отследить производительность, Sysprof покажет вам коллграфы и пламяграфы, используя эти трассы стека JavaScript/C interposed.
Информация о планировщике
Мы часто думаем, что наши программы работают непрерывно, хотя планировщик процессов постоянно меняет один процесс на другой.
Sysprof может включать в себя информацию о времени работы планировщика, чтобы вы могли понять, почему у вас могут быть проблемы с производительностью. Может быть, программа слишком часто переключается между процессорами? Может быть, слишком много других процессов имеют более высокий приоритет?
Все это можно увидеть в мельчайших подробностях.
Запись по шине D-Bus
Наиболее распространенной моделью межпроцессного взаимодействия между приложениями на рабочем столе Linux является шина D-Bus. Она позволяет процессам взаимодействовать различными способами.
Иногда приложения могут использовать эту технологию не слишком эффективно. В других случаях это может быть просто медленная работа приложения в ответ на запрос.
Чтобы помочь отследить подобные проблемы, Sysprof может записывать сообщения на сеансовой и системной шине. Вы можете соотнести время появления этих сообщений с тем, какой код выполняется в ваших профилированных приложениях.
Под конец цикла разработки Fedora Linux 39 я потратил немного времени на оптимизацию некоторых проблем, которые я обнаружил с помощью Sysprof.
Многие из этих улучшений сделаны в кодовых базах, в которые я раньше не вносил свой вклад. Учитывая информацию, полученную от Sysprof и профилирования в Fedora Linux, это не имело значения. Было просто найти и устранить проблемы.
Провайдеры поиска GNOME
Во время создания Sysprof для Fedora Linux 39 я проводил время, тестируя его на своей системе. Я постоянно замечал, что в профилях появляется множество провайдеров поиска, хотя они не имели никакого отношения к тому, что я делал.
По очереди мы рассмотрели каждый провайдер поиска, чтобы понять, что происходит.
Некоторые из них оказалось сложнее исправить, чем другие. Например, gnome-weather требовал добавления сложной структуры данных для определения геопространственного расстояния. Другие были проще и просто требовали избежать дублирования работы.
GLib и GObject
Библиотека GLib предоставляет общие утилиты и структуры данных на языке Си для всевозможных приложений. Она также включает базовую систему типов в виде GObject. Она используется в качестве основы для GTK, а также GNOME Shell.
Обнаружение проблем с производительностью в GLib может иметь далеко идущие последствия, поскольку затрагивает так много приложений и демонов.
Профилируя производительность приложений GTK, я заметил любопытную вещь. Мы проводили ужасно много времени в системе типов, вместо того чтобы выполнять работу приложения.
И снова Sysprof указывает нам прямо на проблему, и через несколько патчей мы видим, что накладные расходы на систему типов в GLib почти исчезли.
systemd-oomd
Убедиться, что системы не используются, очень важно для увеличения времени работы от батареи.
Быстрая запись, пока мой ноутбук простаивал, продолжала показывать systemd-oomd несколько раз в секунду. Как любопытно!
Быстрый взгляд на код и сообщение в списке рассылки показали, что это ожидаемое поведение, но которого потенциально можно избежать.
Одна очень маленькая заплатка позже мы начали добиваться более длительных периодов времени без пробуждения процессора каким-либо кодом. Именно то, что мы искали!
Эмулятор терминала VTE
В Fedora Linux 40 пользователей терминалов ждет одно из значительных улучшений производительности.
VTE – это библиотека для написания эмуляторов терминалов, использующая графический инструментарий GTK. Эта библиотека используется в GNOME Terminal, Console, xfce-terminal и многих других.
Библиотека имеет долгую историю в рамках проекта GNOME, насчитывающую более 20 лет. Фактически, она была одним из первых терминалов, поддерживающих сглаженные шрифты.
Набор функций VTE очень широк. Однако он был разработан в эпоху X11, когда вам повезло, если у вас вообще были рабочие графические драйверы.
Мы можем видеть, как это отразилось на нашей системе. Многие из нас живут в терминалах весь день. Поэтому неэффективность здесь имеет широкое влияние!
Sysprof быстро указывает, что мы тратим огромное количество времени в библиотеке Cairo на отрисовку содержимого терминала на CPU GTK 4 отрисовывает содержимое терминала на GPU поэтому он также должен загружать изображение на GPU!
GTK имеет поддержку для отрисовки пользовательского интерфейса и текста на GPU. Почему бы нам не заставить его делать это!
Немного поработав над рефакторингом VTE, чтобы воспользоваться этим преимуществом, мы можем наблюдать значительное снижение использования процессора при увеличении частоты кадров. В лучшем случае мы рисовали на частоте около 40 Гц, потребляя при этом значительное количество CPU. После рефакторинга мы можем легко достигать 240 Гц при незначительном использовании процессора даже при полноэкранном обновлении.
Пока я улучшал производительность отрисовки VTE, я нашел много других вещей, которые нужно улучшить. Такова жизнь программного обеспечения с такой долгой историей. Двузначный прирост производительности был достигнут за счет оптимизации таких скучных вещей, как использование массивов, декодирование UTF-8, форматы сжатия и обеспечение того, чтобы компилятор «вставлял» то, что вы от него ожидаете.
В итоге мы смогли почти удвоить производительность VTE для многих распространенных случаев использования.
Мы все хотим лучший и более быстрый Fedora Linux. Sysprof пытается сделать так, чтобы вы могли присоединиться и сделать это в ваших разрабатываемых проектах!




Комментарии (0)